You have unlimited access as a PRO member
You are receiving a free preview of 3 lessons
Your free preview as expired - please upgrade to PRO
Contents
Recent Posts
- Object Oriented Programming With TypeScript
- Angular Elements Advanced Techniques
- TypeScript - the Basics
- The Real State of JavaScript 2018
- Cloud Scheduler for Firebase Functions
- Testing Firestore Security Rules With the Emulator
- How to Use Git and Github
- Infinite Virtual Scroll With the Angular CDK
- Build a Group Chat With Firestore
- Async Await Pro Tips
Firestore NoSQL Relational Data Modeling
Episode 85 written by Jeff Delaney
Data modeling in a NoSQL environment is tricky - especially if you come from a RDBMS background (MySQL, Postgres, etc) because you will need to unlearn many of the core principles already solidified in your brain. Firestore uses a document-oriented NoSQL model, similar to MongoDB and CouchDB, which leads to fundamentally different data structuring decisions.
The goal of this lesson is to examine data modeling principles in Firestore with comparisons to SQL. We will sketch out a few common features data modeling scenarios with Firestore, so you don’t get stuck with an unworkable database.
Many developers use NoSQL because they can build first and ask questions later - this is a bad strategy. If you fail to structure your data properly, it may be difficult or impossible to query efficiently and/or scale. I will show you how to ask the right questions throughout this tutorial.
Key Principles
First, keep in Here are few key principles you must understand about Firestore.
- Queries must be fast.
- Collections can be large, documents must be small (< 1MB).
- Data duplication is OK.
- Always ask yourself How will I need to query this data for the end user?
Now let’s look at the three fundamental ways we can structure NoSQL Firestore data:
Root Collections
A root collection keeps all documents of a certain type at the root, providing maximum query flexibility. If you’re unsure of the optimal data model, a root collection your safest bet.

You can model relational data with a root collection by making a reference to a sibling document. For example, every tweet document can be assigned a userId property that points to the user who posted it.
Embedded Data
Embedding simply means saving data it on the document itself, usually in the form of an object/map. For example, we might embed some ranking data inside a user document. A cool feature of Firestore is that you can query based on embedded properties, users.where('ranking.blackBelt', '>=', '300').
users/{userId} |
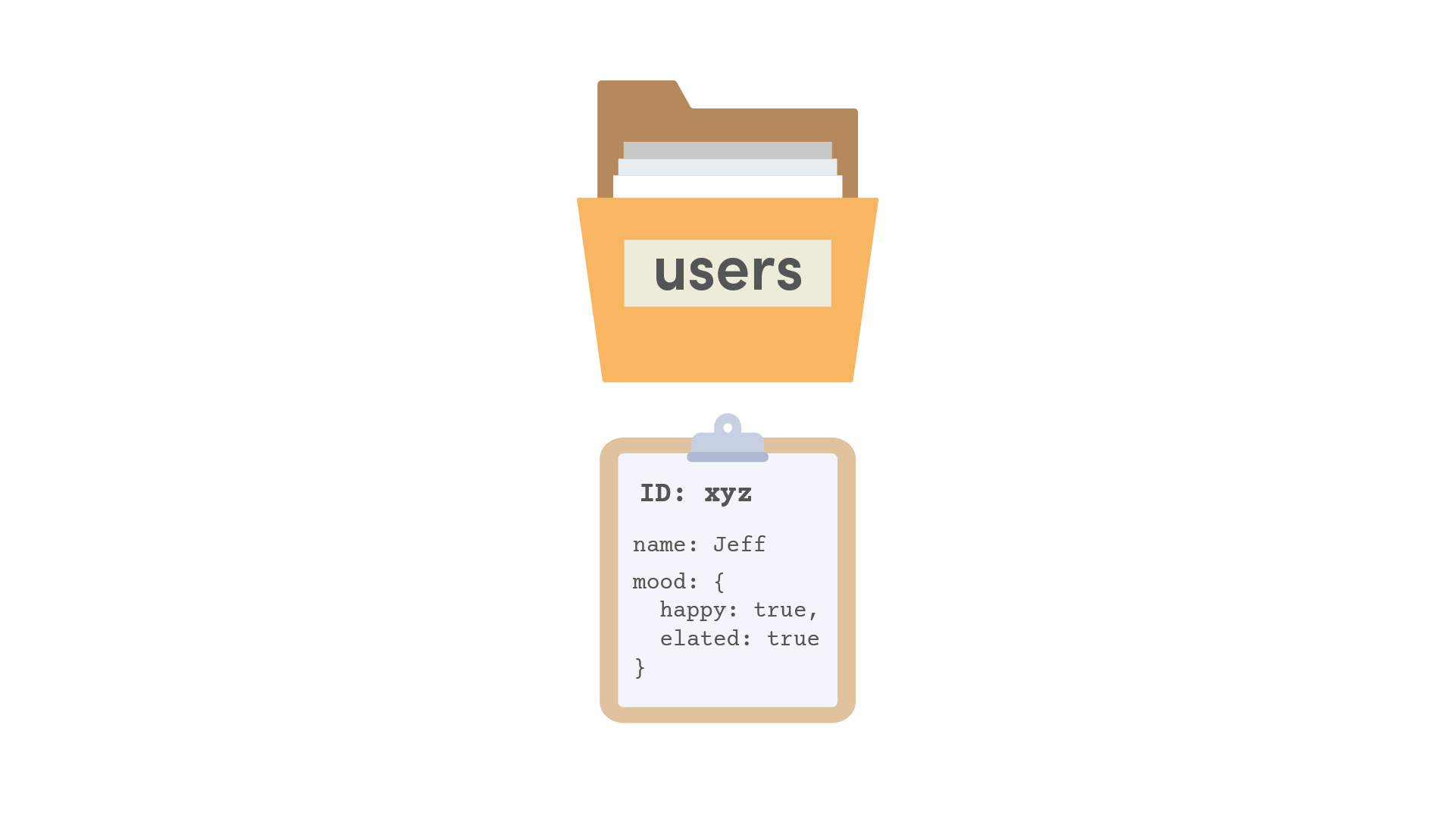
Embedded data is ideal when your max anticipated data size is less than 1MB. If you expect embedded data to exceeded hundreds of records, you should probably be looking at a dedicated collection.
Subcollections
A subcollection is just a collection that is nested under a specific document. They can be great for modeling relational data, assuming your queries will always be scoped to the parent document.
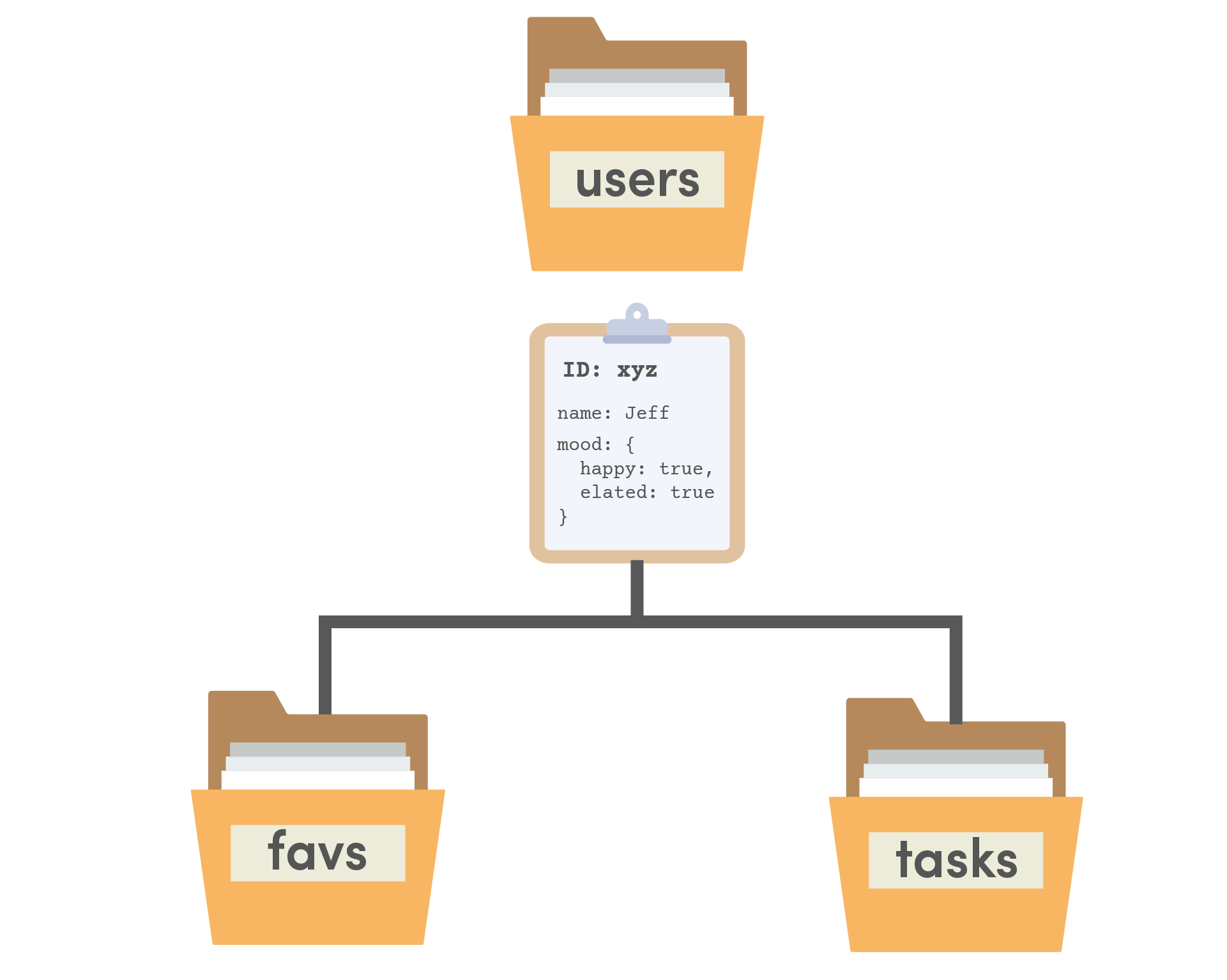
Always ask yourself… Do I need to query this collection across multiple parent documents? If we wanted to query ALL users’ tasks, it would NOT be possible with a subcollection model. This is called a group collection query and it not supported in Firestore at this time.
One-to-Many Relationship
The One-to-Many or Parent-Children relationship represents a connection between two data models, were every instance of the child is owned by the parent. You might express this relationship as user has many tweets and a tweet belongs to a user.
This is perhaps the most common relational structure. In a SQL database, we would manage this relationship by putting a foreign key called user_id on the tweets table.
We can follow a similar pattern in Firestore, but we have several ways to execute this relationship. You should be able to settle on a data structure by asking a few questions.
Will you ALWAYS query the collection scoped to its parent document?
Yes? Subcollection.
In other words, subcollections are ideal for data that does not need to be combined between multiple users.
Is the max data size less than ~1MB??
Yes? Embedded data. When data is small and simple, the embedded structure is usually ideal.
Do you need to query documents across their parents?
Yes? Root Collection.
For example, Tweets belong to a user, but you might also want to get all tweets from all users on a specific day - for that you need a root collection.
One-to-One Relationship
The One-to-One relationship is a connection with another document, were every instance of the child is owned by the parent. For example, a user has one premium membership account. In most cases, you can use embedded data for this type of relationship, but you can also use a root collection where the related document matches the parent document ID.
Many-to-Many Relationship
Many-to-many relationships are the most difficult to model in NoSQL. For example, an actor can be in many movies and a movie can have many actors.
Many-to-Many Middle Man Collection
You can model relationships by proceeding through a third model. For example, we might have three root collections of actors, movies, and roles. Notice how the document ID in the roles collection is a actorId_movieId - while not required, this does enforce uniqueness on the relational document.
actors/{bradpitt} |
If we want all the movies an actor has starred in, we can run roles.where('actorId', '==', 'bradpitt').
If we want all the actors from a given movie, we can run roles.where('movieId', '==', 'fightclub').
Embedded Many-to-Many Relationships
We can also model this relationship by embedding and duplicating some data. This is great when (1) the data size is small and (2) you only need to show a summary of the related document.
actors/{bradpitt} |
Now we can simply read data from the document directly. Get all of Brad Pitt’s movies with actors.doc('bradpitt') and vice versa.
Subcollection Many-to-Many Relationships
Rather than keep track of an ID in a root collection, you can also model many-to-many by combining a subcollection with embedded data. See this one in action in the Group Chat model below.
Structuring Likes, Hearts, Thumbs-Up, Votes, Etc.
Now let’s look at some real world data models. Likes, Hearts, Thumbs-Up, and Votes are very common relational features in web development and usually need to scale to millions of records. Here’s what our data relationships look like:
- One-to-Many: User to Tweets
- Many-to-Many: Tweets to Users through Likes
Data Model

Users (root collection): Basic profile information about a user.
Likes (root collection): Likes is the middle-man collection that must have both a userId and tweetId to maintain a Many-to-Many relationship.
Tweets (root collection): Tweets must have a userId property because they belong to a user. We will also use aggregation to save a total likeCount directly on the document.
You must Aggregate to Scale
The only issue with this model is that it doesn’t scale if you need to count millions of likes. To solve this problem, I created a video about Firestore data aggregation that uses a cloud function to sum up data as needed. We could use it increment or decrement the likeCount property on a tweet when they are created or deleted.
Sample Queries
Get all tweets liked by a user:
db.collection('likes').where('userId', '==', userId) |
Get the total amount of likes for tweet (assuming you aggregate):
db.collection('tweets').doc(tweetId) |
Get a user’s tweets:
db.collection('tweets').where('userId', '==', userId) |
Group Chat
The next model we’ll look at is a group chat app because this is so common in Firebase apps. Let’s imagine we’re building an app similar to Slack in this example. Here we have:
- One-to-Many: Chat to Users via embedding
- Many-to-Many: Messages to Users via the Chats Subcollection
Data Model
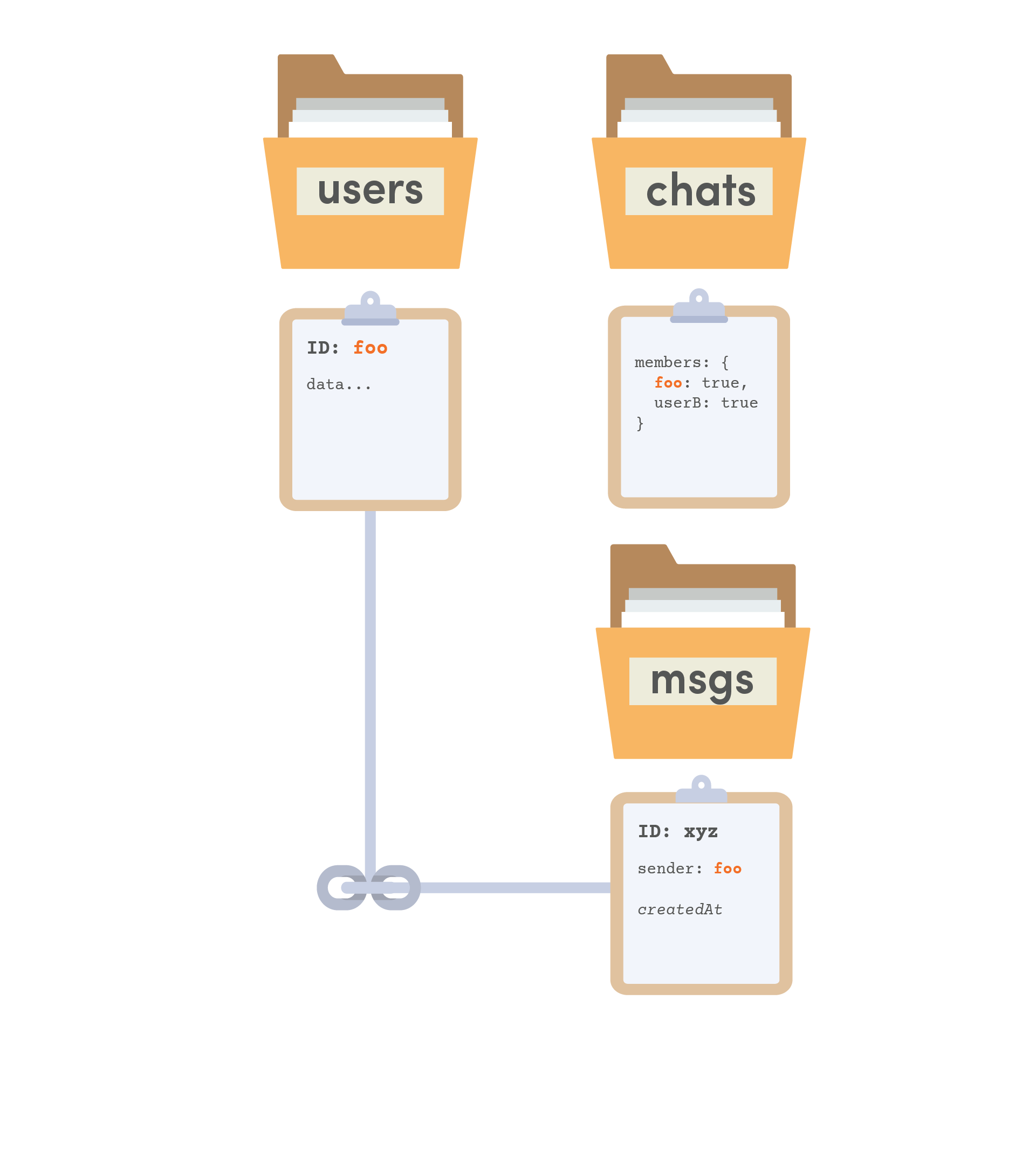
Users (root collection): Basic profile information about a user.
Chats (root collection): A channel contains basic information about the channel itself, as well as an object of it’s members. The members object is important because it allows us to query all channels that a member belongs to.
Messages (sub collection of a channel): It is unlikely that we will need to query messages across multiple channels, so they are best organized as a subcollection of a channel. We can also reference the user on each document, which sets up a many-to-many relationship.
Sample Queries
Get all channels that a user belongs to:
db.collection('chats').where('users.someUserId', '==', true) |
Get all messages in a channel ordered by createdAt:
db.collection('chats') |
Get a user profile from a message they posted:
db.collection('users').doc(message.userId) |
The End (for now)
I have a bunch of other data models sketched out for real-world features such as a shopping cart, follower system, threaded comments, and more. Keep your eyes pealed for a follow up with more advanced data structures in the near future.